
前言
目前的计算机图像识别,透过现象看本质,主要分为两大类:
- 基于规则运算的图像识别,例如颜色形状等特征匹配。
- 基于统计的图像识别,例如机器学习自动提取特征,并通过级联多特征匹配。
- 场景:特征匹配方法适合固定的场景或物体识别,机器学习方法适合大量具有共同特征的场景或物体识别。
- 优劣:无论从识别率,准确度,还是适应多变场景来讲,机器学习都是优于特征匹配方法的,前提你有
大量的数据来训练分类器。如果是仅仅是识别特定场景、物体或者形状,使用模板匹配方法更简单更易于实现。
本文目标,实现在iOS客户端,通过摄像头发现并标记目标。
方案选择
iOS 客户端快速实现图像识别的两种方案:
| 开源库 | 公司 | 方案说明 |
|---|---|---|
| TensorFlow | AlphaGo 战胜世界围棋冠军,人工智能大火,谷歌 2016 年开源了其用来制作 AlphaGo 的深度学习系统 Tensorflow,而且 Tensorflow 支持了 iOS,Android 等移动端。 | |
| OpenCV | Intel | OpenCV 于 1999 年由 Intel 建立的,跨平台的开源计算机视觉库,主要由 C 和 C++ 代码构成,有 Python、Ruby、MATLAB 等语言的接口,支持 iOS,Android 等移动设备。 |
TensorFlow && OpenCV

结论,虽然都是开源库,TensorFlow 侧重点偏向于机器学习,OpenCV 偏向于图像处理。从推出时间,代码迭代,资料的丰富度,以及前辈已经给踩平的坑来讲,本文选择 OpenCV 实现。
OpenCV 中常用图像识别的方法对比
| 方法名称 | 适用场景 | 示例 |
|---|---|---|
| 模板匹配 | 适合固定的场景、物体或特定形状的图片识别 | 1. 某公司的 Logo 图标,假设图标是固定的; 2. 适用于某个图片是另外一张大图的一部分的场景; 3. 例如五角星形状固定,可转换为边框匹配。 |
| 特征点检测 | 适合标记两幅图片中相同的特征点 | 1. 有相同部分的照片拼接,视频运动追踪; 2. 例如全景图片的拼接,长图的拼接; 3. 监控视频中的目标跟踪。 |
| 机器学习 | 适合识别某类有多种状态的场景或物体识别 | 1. 人脸识别、人眼识别,身体识别等等; 2. 支付宝扫福,福字有成千上万种写法。 |
备注:基于机器学习训练分类器用来分类的方法,依赖于训练数据,给机器提供大量包含目标的正确数据和不包含目标的错误背景数据,让机器来总结提取特征,适合识别某类有多种状态的场景或物体识别。
集成 OpenCV
iOS项目集成OpenCV,主要有两种方法:
-
从OpenCV官网下载 opencv2.framework 框架,拖入即可,导入依赖的库,具体集成方法见我的另外一篇文章iOS集成OpenCV。
-
CocoaPods 方式集成,Pod 文件中配置
pod 'OpenCV',此方法简单,推荐。
模板匹配法
首先要做的肯定是从 iPhone 摄像头获取视频帧,从输出视频流代理AVCaptureVideoDataOutputSampleBufferDelegate的代理方法中获取视频帧。
#pragma mark - 获取视频帧,处理视频
- (void)captureOutput:(AVCaptureOutput *)captureOutput didOutputSampleBuffer:(CMSampleBufferRef)sampleBuffer fromConnection:(AVCaptureConnection *)connection;
然后,需要将视频帧转换为 OpenCV 能够用的 cv::Mat 矩阵,OpenCV 运算是以矩阵 Mat 为基础的。涉及大量 CPU 运算,需要将视频帧对象高效转换为 OpenCV 能够使用矩阵 cv::Mat,否则手机发烫严重。
模板匹配法不需要颜色,通过设置相机输出格式是YpCbCr格式,直接从内存读取灰度图像,减少 CPU 运算。
/**
* 高效将视频流转换为 Mat 图像矩阵
* Efficiently convert video streams to Mat image matrices
@param sampleBuffer 视频流(video stream)
@return OpenCV 可用的图像矩阵(OpenCV available image matrix)
*/
+(cv::Mat)bufferToGrayMat:(CMSampleBufferRef) sampleBuffer{
CVPixelBufferRef pixelBuffer = CMSampleBufferGetImageBuffer(sampleBuffer);
OSType format = CVPixelBufferGetPixelFormatType(pixelBuffer);
if (format != kCVPixelFormatType_420YpCbCr8BiPlanarFullRange) {
OOBLog(@"Only YUV is supported"); // Y 是亮度,UV 是颜色
return cv::Mat();
}
CVPixelBufferLockBaseAddress(pixelBuffer, 0);
void *baseaddress = CVPixelBufferGetBaseAddressOfPlane(pixelBuffer, 0);
CGFloat width = CVPixelBufferGetWidth(pixelBuffer);
videoRenderWidth = width; // 保存渲染宽度
CGFloat colCount = CVPixelBufferGetBytesPerRowOfPlane(pixelBuffer, 0);
if (width != colCount) {
width = colCount; // 如果有字节对齐
}
CGFloat height = CVPixelBufferGetHeight(pixelBuffer);
cv::Mat mat(height, width, CV_8UC1, baseaddress, 0);
CVPixelBufferUnlockBaseAddress(pixelBuffer, 0);
return mat;
}
如果相机需要设置为BGRA格式,这时候需要用其他方法获取,如果是需要获取灰度图像,不推荐此方法,CPU 占有率较前一种高的多。
其中旋转 90 度和镜像翻转,根据获取的图像是否需要,可通过设置摄像头输出避免,前置和后置摄像头设置不同。
///MARK: - 将CMSampleBufferRef转为cv::Mat
+(cv::Mat)bufferToMat:(CMSampleBufferRef) sampleBuffer{
CVImageBufferRef imgBuf = CMSampleBufferGetImageBuffer(sampleBuffer);
//锁定内存
CVPixelBufferLockBaseAddress(imgBuf, 0);
// get the address to the image data
void *imgBufAddr = CVPixelBufferGetBaseAddress(imgBuf);
// get image properties
int w = (int)CVPixelBufferGetWidth(imgBuf);
int h = (int)CVPixelBufferGetHeight(imgBuf);
// create the cv mat
cv::Mat mat(h, w, CV_8UC4, imgBufAddr, 0);
//转换为灰度图像
cv::Mat edges;
cv::cvtColor(mat, edges, CV_BGR2GRAY);
//旋转90度
cv::Mat transMat;
cv::transpose(mat, transMat);
//翻转,1是x方向,0是y方向,-1位Both
cv::Mat flipMat;
cv::flip(transMat, flipMat, 1);
CVPixelBufferUnlockBaseAddress(imgBuf, 0);
return flipMat;
}
最后,视频帧矩阵与模板矩阵对比,此时获取了模板 UIImage 的矩阵 templateMat 和视频帧的矩阵 flipMat,只需要用 OpenCV 的函数对比即可。
/**
对比两个图像是否有相同区域
@return 有为Yes
*/
-(BOOL)compareInput:(cv::Mat) inputMat templateMat:(cv::Mat)tmpMat{
int result_rows = inputMat.rows - tmpMat.rows + 1;
int result_cols = inputMat.cols - tmpMat.cols + 1;
cv::Mat resultMat = cv::Mat(result_cols,result_rows,CV_32FC1);
cv::matchTemplate(inputMat, tmpMat, resultMat, cv::TM_CCOEFF_NORMED);
double minVal, maxVal;
cv::Point minLoc, maxLoc, matchLoc;
cv::minMaxLoc( resultMat, &minVal, &maxVal, &minLoc, &maxLoc, cv::Mat());
// matchLoc = maxLoc;
// NSLog(@"min==%f,max==%f",minVal,maxVal);
dispatch_async(dispatch_get_main_queue(), ^{
self.similarLevelLabel.text = [NSString stringWithFormat:@"相似度:%.2f",maxVal];
});
if (maxVal > 0.7) {
//有相似位置,返回相似位置的第一个点
currentLoc = maxLoc;
return YES;
}else{
return NO;
}
}
模板匹配法优化
此时,我们已经对比两个图像的相似度了,其中maxVal越大表示匹配度越高,1为完全匹配,一般想要匹配准确,需要大于0.7。
但此时我们发现一个问题,我们摄像头离图像太远或者太近,都无法识别,只有在特定的距离才能够识别。
这是因为模板匹配法,只是死板的拿模板图像去和摄像头读取的图像进行比较,放大缩小都不行。
我们做些优化,按照图像金字塔的方法,将模板进行动态的放大缩小,只要能够匹配,说明图像就是一样的,这样摄像头前进后退都能够识别。我们将识别出的位置和大小保存在数组中,用矩形方框来标记位置。至于怎么标记,就不细说了,方法很多。
/**
* 对比两个图像是否有相同区域
* Compare whether two images have the same area
@param inputMat 缩放后的视频图像矩阵(Scaled video image matrix)
@param tmpMat 待识别的目标图像矩阵(Target image matrix to be identified)
@param scale 视频缩放比例(video scaling)
@param similarValue 设置的对比相似度阈值(set contrast similarity threshold)
@param videoFillWidth 视频图像字节补齐宽度(Video image byte fill width)
@return 对比结果,包含目标坐标,相似度(comparison result, including target coordinates, similarity)
*/
+(NSDictionary *)compareInput:(Mat) inputMat templateMat:(Mat)tmpMat VideoScale:(CGFloat)scale SimilarValue:(CGFloat)similarValue VideoFillWidth:(CGFloat)videoFillWidth{
// 将待比较的图像缩放至视频宽度的 20% 至 50%
NSArray *tmpArray = @[@(0.2),@(0.3),@(0.4),@(0.5)];
int currentTmpWidth = 0; // 匹配的模板图像宽度
int currentTmpHeight = 0; // 匹配的模板图像高度
double maxVal = 0; // 相似度
cv::Point maxLoc; // 匹配的位置
for (NSNumber *tmpNum in tmpArray) {
CGFloat tmpScale = tmpNum.floatValue;
// 待比较图像宽度,将待比较图像宽度缩放至视频图像的一半左右
int tmpCols = inputMat.cols * tmpScale;
// 待比较图像高度,保持宽高比
int tmpRows = (tmpCols * tmpMat.rows) / tmpMat.cols;
// 缩放后的图像
Mat tmpReMat;
cv::Size tmpReSize = cv::Size(tmpCols,tmpRows);
resize(tmpMat, tmpReMat, tmpReSize);
// 比较结果
int result_rows = inputMat.rows - tmpReMat.rows + 1;
int result_cols = inputMat.cols - tmpReMat.cols + 1;
if (result_rows < 0 || result_cols < 0) {
break;
}
Mat resultMat = Mat(result_cols,result_rows,CV_32FC1);
matchTemplate(inputMat, tmpReMat, resultMat, TM_CCOEFF_NORMED);
double minVal_temp, maxVal_temp;
cv::Point minLoc_temp, maxLoc_temp, matchLoc_temp;
minMaxLoc( resultMat, &minVal_temp, &maxVal_temp, &minLoc_temp, &maxLoc_temp, Mat());
maxVal = maxVal_temp;
if (maxVal >= similarValue) {
maxLoc = maxLoc_temp;
currentTmpWidth = tmpCols;
currentTmpHeight = tmpRows;
break;
}
}
if (maxVal >= similarValue) {
// 目标图像按照缩放比例恢复
CGFloat zoomScale = 1.0 / scale;
CGRect rectF = CGRectMake(maxLoc.x * zoomScale, maxLoc.y * zoomScale, currentTmpWidth * zoomScale, currentTmpHeight * zoomScale);
NSDictionary *tempDict = @{kTargetRect:NSStringFromCGRect(rectF),
kSimilarValue:@(maxVal),
kVideoFillWidth:@(videoFillWidth)};
return tempDict;
}else{
NSDictionary *tempDict = @{kTargetRect:NSStringFromCGRect(CGRectZero),
kSimilarValue:@(maxVal),
kVideoFillWidth:@(videoFillWidth)};
return tempDict;
}
}
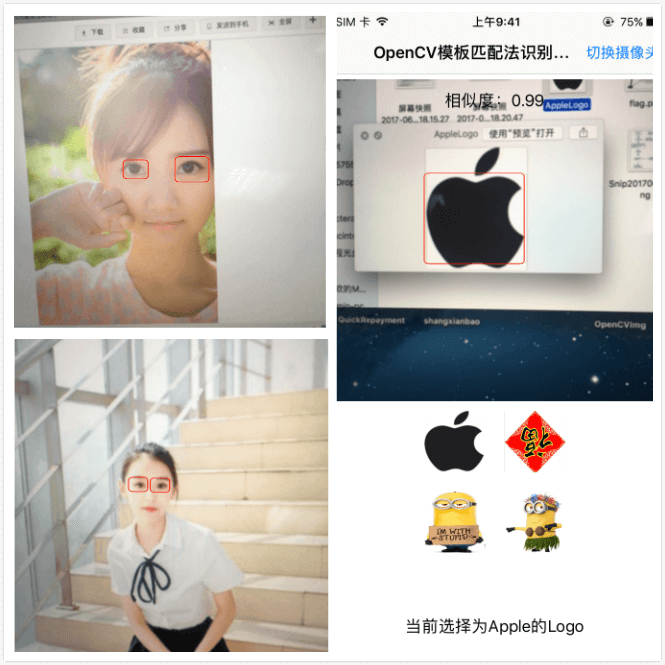
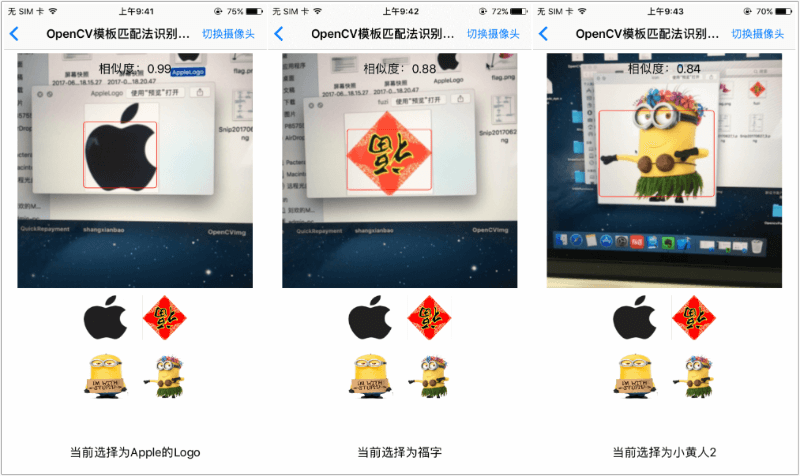
模板匹配法实现效果图
机器学习训练分类器方法识别图像
机器学习方法适合批量提取大量图片的特征,而且如果样本不标准或者有错误,也会导致分类器识别正确率降低。
训练分类器的方法,请自行 google 查找,本篇不再详细说明。
大量的训练数据如何获取,例如人脸分类器需要的正样本人脸图像几千张,负样本需要为正样本的3倍左右。我的解决思路为从摄像头录制待识别物体,从视频帧中生成 PNG 格式的正样本,再拍摄不包含待识别物体的背景,仍旧从视频中自动生成 PNG 格式的负样本,最后对图片进行缩放统一。
加载训练完成的分类器
训练完成后会一般会生成一个 XML 格式的文件,我们加载这个 XML 文件,就可以用其来识别物体了,这里我们使用 OpenCV 官方库中人眼识别库haarcascade_eye_tree_eyeglasses.xml,我们从GitHub上面下载开源库 OpenCV 的源代码,目前最新版本为 4.1.0,分类器在 OpenCV 项目的 /data 目录下的文件夹中,XML 格式文件就是。
加载训练好的分类器文件需要用到加载器,我们定义一个加载器属性对象:
cv::CascadeClassifier icon_cascade;//分类器
加载器加载 XML 文件,加载成功返回 YES。
//加载训练文件
NSString *bundlePath = [[NSBundle mainBundle] pathForResource:@"haarcascade_eye_tree_eyeglasses.xml" ofType:nil];
cv::String fileName = [bundlePath cStringUsingEncoding:NSUTF8StringEncoding];
BOOL isSuccessLoadFile = icon_cascade.load(fileName);
isSuccessLoadXml = isSuccessLoadFile;
if (isSuccessLoadFile) {
NSLog(@"Load success.......");
}else{
NSLog(@"Load failed......");
}
使用分类器识别图像
我们是从摄像头获取图像,仍需把视频帧转换为 OpenCV 能够使用的cv::Mat矩阵格式,按照上面已知的方法转换,假设我们已经获取了视频帧转换好的灰度图像矩阵cv::Mat imgMat,那我们用OpenCV的API接口来识别视频帧,并把识别出的位置转换为 Frame 存在数组中返回,我们可以随意使用这些 Frame 来标记识别出的位置。
//获取计算出的标记的位置,保存在数组中
-(NSArray *)getTagRectInLayer:(cv::Mat) inputMat{
if (inputMat.empty()) {
return nil;
}
//图像均衡化
cv::equalizeHist(inputMat, inputMat);
//定义向量,存储识别出的位置
std::vector<cv::Rect> glassess;
//分类器识别
icon_cascade.detectMultiScale(inputMat, glassess, 1.1, 3, 0);
//转换为Frame,保存在数组中
NSMutableArray *marr = [NSMutableArray arrayWithCapacity:glassess.size()];
for (NSInteger i = 0; i < glassess.size(); i++) {
CGRect rect = CGRectMake(glassess[i].x, glassess[i].y, glassess[i].width,glassess[i].height);
NSValue *value = [NSValue valueWithCGRect:rect];
[marr addObject:value];
}
return marr.copy;
}
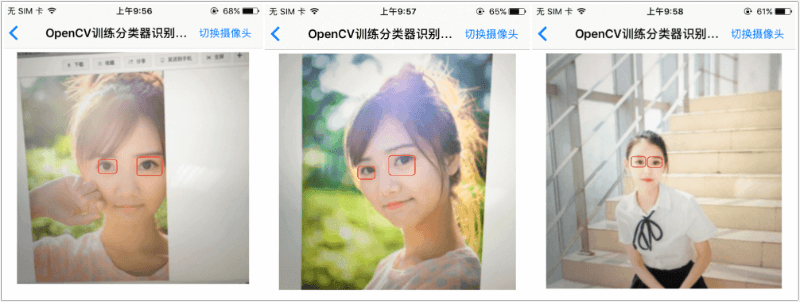
分类器识别图像效果图
OpenCV 其他图像处理
- 原图像
- 直方图均衡化
- 图像二值化
- 摄像头预览
- 灰度图
- 轮廓图

如果您觉得有所帮助,请在 GitHub OOBDemo 上赏个Star ⭐️,您的鼓励是我前进的动力。